Motivation
River is a Python library for online machine learning. One of the main features of River is its support for data streams, which are continuous streams of data that are produced and consumed in real-time. This makes it well-suited for handling large volumes of data, as well as for handling data that is generated continuously.
I started contributing to the project in February 2019, mainly in the stats and time_series modules.
Some users have reported that they require high performance for online statistics tasks and have experienced performance issues with the library, such as user fox-ds for computing rolling quantiles.
In our last IRL river devs meeting at Ile d’Yeu (June 2022), I suggested exploring the possibility of mitigating some of the bottlenecks in River in a compiled language like Rust.
I chose Rust for this task due to its known benefits like performance, and boring to maintain, as well as its thriving ecosystem and excellent tooling.
Taking this idea forward, I developed the watermill crate (Rust library), which contains the stats module of River implemented in Rust. Testing the Rust bindings in the River stats module showed promising results, with a significant performance boost
| Statistics | Pure Python (s) | Rust binding (s) | x times improvement |
|---|---|---|---|
| Quantile | 2.359 | 0.148 | 15.955 |
| Peak To Peak | 0.216 | 0.47 | 4.609 |
| EWMean | 0.158 | 0.105 | 1.512 |
| EWVar | 0.426 | 0.104 | 4.075 |
| IQR | 4.541 | 0.169 | 26.846 |
| Kurtosis | 1.785 | 0.106 | 16.872 |
| Skewness | 1.086 | 0.105 | 10.354 |
| Rolling Quantile | 323.520 | 77.247 | 4.573 |
| Rolling IQR | 636.528 | 76.688 | 9.113 |
The benchmark is the total time to update 1 million of data. For rolling statistics, the window is 1 million and there are 2 million updates.
The significant performance improvement we saw in the proof of concept for the Rust bindings motivated us to integrate Rust into the stats module. In the following sections, we will dive into the technical details of how we called a Rust struct from Python and bind it into the stats module, as well as how we built Python wheels with the Rust bindings using Github Action CI.
Calling a Rust Struct from Python
To call a Rust struct from Python, we can use the PyO3 library, which enables the development of Python extensions in Rust.
PyO3 is a library for developing Python extensions in Rust. It provides Rust bindings for the Python C API and allows you to write Rust code that can be called from Python.
To use PyO3, we need to add it to our Cargo.toml file as a dependency, along with other dependencies such as watermill, bincode, and serde (we will cover that further). Our Cargo.toml file should look like this:
[package]
name = "river"
version = "0.1.0"
authors = ["Adil Zouitine <adilzouitinegm@gmail.com>"]
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[lib]
name = "river"
path = "rust_src/lib.rs"
crate-type = ["cdylib"]
[dependencies]
pyo3 = { version = "0.16.5", features = ["extension-module"] }
watermill = "0.1.0"
bincode = "1.3.3"
serde = { version = "1.0", features = ["derive"] }
Once you have added PyO3 as a dependency and annotated your Rust functions with the appropriate attributes (we will cover that further), you can use the PyO3library to create a Python extension module that can be imported into a Python script.
In a typical Rust project, the main source code directory is called src. However, in the Cargo.toml file shown above, the main source code directory has been renamed to rust_src. This is because the src directory confuse for River maintainers. By renaming the Rust source directory to rust_src and specifying this path in the Cargo.toml file, we can keep the Rust and Python source code separate and avoid any confusion. The lib.rs file, which contains the main code for the Rust crate, is located in the rust_src directory. By specifying the path element in the Cargo.toml file, the cargo build tool is able to locate and compile the crate’s source code, even if it is located in a directory other than the default src directory.
Now that we’ve set up our Rust project and configured our dependencies, let’s dive into the code. We can create our Rust struct and annotate it with #[pyclass] to make it accessible from Python. For example, if we have a struct called RsEWMean, we can annotate it this way:
use pyo3::prelude::*;
use watermill::{ewmean::EWMean, ...};
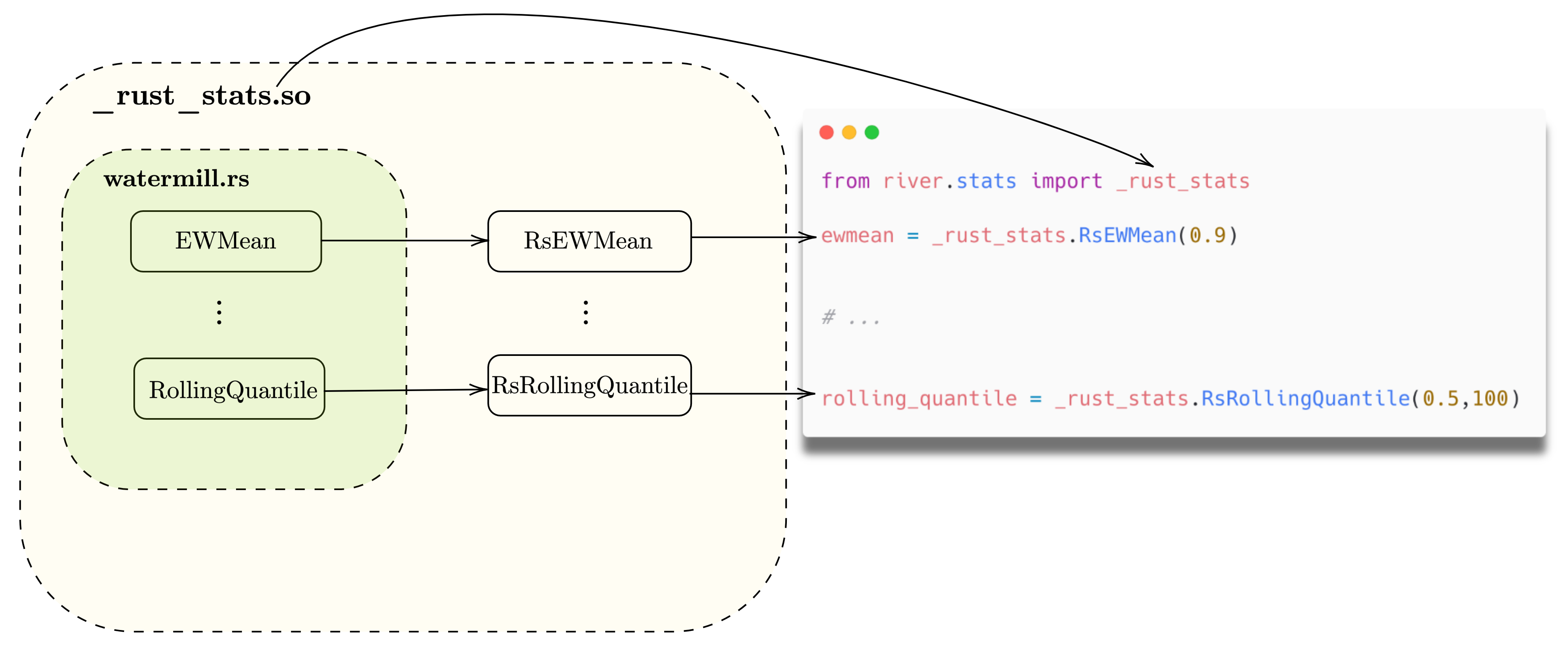
#[pyclass(module = "river.stats._rust_stats")]
pub struct RsEWMean {
ewmean: EWMean<f64>
}
The full code for the EWMean struct is available here.
The #[pyclass(module = "river.stats._rust_stats")] annotation on the Rust struct indicates that it will be made available in the river.stats._rust_stats module, which corresponds to the _rust_stats.so file. This enables the Rust struct to be used from Python as a module, allowing it to be easily called from Python. The Python interpreter will load the .so file and use it to execute the Rust code.
To make the methods of our struct available from Python, we can annotate them with #[pymethods]. For example, if our RsEWMean struct has methods called new, update, and get, we can annotate them this way:
use pyo3::prelude::*;
#[pymethods]
impl RsEWMean {
#[new]
pub fn new(alpha: f64) -> RsEWMean {
RsEWMean {
ewmean: EWMean::new(alpha),
alpha,
}
}
pub fn update(&mut self, x: f64) {
self.ewmean.update(x);
}
pub fn get(&self) -> f64 {
self.ewmean.get()
}
}
To save and load objects in the river library, we use Python’s pickle module, allowing them to be easily stored and transferred between programs.
To use pickle with our Rust struct, we need to ensure that the struct is properly serializable and deserializable. To do this, we can use the serde crate and annotate the struct with #[derive(Serialize, Deserialize)]. This allows the struct to be serialized and deserialized using the serialize and deserialize functions provided by serde.
use serde::{Deserialize, Serialize};
use watermill::{ewmean::EWMean, ...};
#[derive(Serialize, Deserialize)]
#[pyclass(module = "river.stats._rust_stats")]
pub struct RsEWMean {
ewmean: EWMean<f64>,
alpha: f64,
}
In addition to the #[derive(Serialize, Deserialize)] annotation, we also need to add the following three methods to the struct’s implementation to enable proper serialization and deserialization from Python:
use pyo3::prelude::*;
use pyo3::types::PyBytes;
use bincode::{deserialize, serialize};
#[pymethods]
impl RsEWMean {
// Other methods...
pub fn __setstate__(&mut self, state: &PyBytes) -> PyResult<()> {
// Deserialize the data contained in the PyBytes object
// and update the struct with the deserialized values.
*self = deserialize(state.as_bytes()).unwrap();
Ok(())
}
pub fn __getstate__<'py>(&self, py: Python<'py>) -> PyResult<&'py PyBytes> {
// Serialize the struct and return a PyBytes object
// containing the serialized data.
Ok(PyBytes::new(py, &serialize(&self).unwrap()))
}
pub fn __getnewargs__(&self) -> PyResult<(f64,)> {
// Return the arguments needed to create a new instance
// of the struct.
Ok((self.alpha,))
}
}
The __setstate__ method is called when our struct is deserialized and receives a PyBytes object containing the serialized data. We use the deserialize function from the bincode crate to deserialize the data and update our struct with the deserialized values. The __getstate__ method is called when our struct is serialized and receives a Python object. We use the serialize function from the bincode crate to serialize our struct and return a PyBytes object containing the serialized data. The __getnewargs__ method is called when our struct is constructed from its deserialized state and returns the arguments needed to create a new instance of our struct. In this case, it returns the alpha parameter.
These methods are necessary to avoid the following error when calling the new method of our struct from Python:
RsEWMean.__new__() missing 1 required positional argument: 'alpha'
This error is due to a known issue in PyO3. By implementing these methods, we can avoid the error and properly deserialize and construct our struct from Python.
The Rust function defines a Python module in the rust_src/lib.rs file. This file is the main source code file for the crate and is located in the rust_src directory.
To define a Python module in Rust, the lib.rs file includes a function annotated with the #[pymodule] attribute. This function takes two arguments: a Python object and a reference to a PyModule object. The Python object represents the Python interpreter and allows Rust to access Python objects and functions. The PyModule object represents the Python module and allows Rust to add classes and functions to the module, making them accessible from Python.
For example, to define a Python module called _rust_stats in Rust, you can use the following code in the lib.rs file:
use pyo3::prelude::*;
#[pymodule]
fn _rust_stats(_py: Python, m: &PyModule) -> PyResult<()> {
m.add_class::<RsEWMean>()?;
Ok(())
}
This code defines a Rust function called _rust_stats that is annotated with the #[pymodule] attribute. The _rust_stats function takes two arguments: a Python object and a reference to a PyModule object. The function returns a PyResult object, which represents the result of a Rust-to-Python call. If the call is successful, the Ok variant of the PyResult is returned. If an error occurs, the Err variant is returned.
To add a Rust struct called RsEWMean to the _rust_stats module, call the add_class method on the m object, which is a reference to the _rust_stats Python module. The add_class method takes a generic type parameter that specifies the Rust class to be added to the module. In this case, the Rust class is RsEWMean. The ::<> syntax is used to specify the type parameter. The add_class method returns a PyResult object, which represents the result of the Rust-to-Python call. If the call is successful, the Ok variant of the PyResult is returned. If an error occurs, the Err variant is returned.
Overall, the _rust_stats function defines a Python module called _rust_stats that can be imported and used from Python. The module contains a Rust class called RsEWMean, which can be accessed and used like any other Python class.
The full implementation of lib.rs is here.
Rust binding
Integration of the Rust binding in River
To integrate the Rust binding into River, we need to create a few files and modify some existing files.
First, we need to modify a MANIFEST.in file which tells the setup.py file what files to include in the distribution package.
The MANIFEST.in file should look like this:
global-include *.pyx
global-include *.pxd
include river/datasets/*.csv
include river/datasets/*.gz
include river/datasets/*.zip
include river/stream/*.zip
include Cargo.toml
recursive-include rust_src *
To integrate the Rust binding into River, we need to create a few files and modify some existing files.
The recursive-include rust_src * line in the MANIFEST.in file tells the setup.py file to include all files in the rust_src directory and its subdirectories in the distribution package. This allows the Rust binding code, which is located in the rust_src directory, to be included in the distribution package and made available to users of the river library.
Next, we need to create a stub file called stats/_rust_stats.pyi which defines the types of the Python objects that will be created from the Rust structs.
The stub file can provide documentation and other information about the RsEWMean class’s methods, which can be helpful for developers who are using the class. This point is optional.
The stats/_rust_stats.pyi file should look like this:
class RsEWMean:
def __init__(self, alpha: float): ...
def update(self, x: float): ...
def get(self) -> float: ...
Finally, we need to create a wrapper for the Rust binding in the stats module. This wrapper is necessary because the stats in River are instances of stats.base.Univariate, but the Rust binding does not inherit from this class. To create a wrapper, we can define a new class called EWMean which extends stats.base.Univariate and contains an instance of RsEWMean from the Rust binding. The stats module should contain the following code:
from river import stats
from river.stats import _rust_stats # <- Pay attention here
class EWMean(stats.base.Univariate):
"""Exponentially weighted mean.
Parameters
----------
alpha
The closer `alpha` is to 1 the more the statistic will adapt to recent values.
Attributes
----------
mean : float
The running exponentially weighted mean.
"""
def __init__(self, alpha=0.5):
if not 0 <= alpha <= 1:
raise ValueError("q is not comprised between 0 and 1")
self.alpha = alpha
self._ewmean = _rust_stats.RsEWMean(alpha) # <- Pay attention here
self.mean = 0
@property
def name(self):
return f"ewm_{self.alpha}"
def update(self, x):
self._ewmean.update(x)
return self
def get(self):
return self._ewmean.get()
To integrate the Rust binding into River, we need to modify the setup.py file to include the Rust extension in the package.
We can ensure that the Rust binding is built and made available to users of the river library when they install the package.
The setup.py file should look like this:
import platform
...
import setuptools
from setuptools_rust import Binding, RustExtension
...
setuptools.setup(
...
ext_modules=cythonize(
module_list=[
setuptools.Extension(
"*",
sources=["**/*.pyx"],
include_dirs=[get_include()],
libraries=[] if platform.system() == "Windows" else ["m"],
define_macros=[("NPY_NO_DEPRECATED_API", "NPY_1_7_API_VERSION")],
)
],
compiler_directives={
"language_level": 3,
"binding": True,
"embedsignature": True,
},
),
rust_extensions=[RustExtension("river.stats._rust_stats", binding=Binding.PyO3)],
# rust extensions are not zip safe, just like C-extensions.
zip_safe=False,
)
The full code is here.
The setup.py file is used to build and distribute the Python package. The setuptools and setuptools_rust libraries are used to build and distribute the package. The setuptools.setup function defines the package’s configuration, including the package’s name, version, dependencies, and other information.
The ext_modules parameter is used to specify the Cython extensions that will be built. Cython is a language that allows us to write Python-like code that can be compiled to C. In the setup.py above, we use cythonize to compile the Cython extensions from all .pyx files in the project.
The rust_extensions parameter is used to specify the Rust extensions that will be built. The RustExtension class is used to define a Rust extension, and the binding parameter is used to specify how the Rust code will be called from Python. In the setup.py above, we use Binding.PyO3 which specifies that we will use the PyO3 library to call the Rust code from Python.
The command : python setup.py build_rust --inplace --release is used to build a Rust project that is being used from Python. The setup.py file is a Python script that specifies the build instructions for the project, and the build_rust argument tells the script to build the Rust portion of the project. The --inplace flag specifies that the Rust project should be built in place, meaning that the built files will be placed in the same directory as the River source code. The --release flag tells the build tool to build the project in release mode, which enables optimizations and disables debugging information in the resulting binary.
Building Python wheels with Rust binding
One reason to build a Python wheel is to make it easier for users to install the package. Instead of having to compile the package from source code, users can simply install the pre-built wheel file. This can be especially useful when the package includes compiled code or extensions, which can be difficult for users to build on their own.
Another reason to build a Python wheel is to make it easier to distribute the package. Wheels are a standardized format, so users can be confident that the package will work on their system if they have a compatible version of Python installed. This can be especially useful for packages that are intended to be used on a wide range of systems, as it allows the package maintainers to build and distribute a single package that many users can use.
Building Python wheels that include compiled code can be a painful process for developers. It requires managing multiple build environments and ensuring that the compiled code is compatible with all the different systems the wheel may be installed on. This can be particularly challenging when building wheels for binary extensions that need to be compiled against different versions of the C library or other system libraries.
To alleviate this pain, Pypa’s cibuildwheels tool provides a continuous integration (CI) service that builds wheels for multiple platforms and Python versions. By specifying your package’s dependencies and build requirements in a configuration file, developers can easily create wheels compatible with a wide range of systems without the burden of building and testing on multiple platforms themselves.
In short, cibuildwheels is a game changer for developers as it significantly simplifies the often painful process of building Python wheels with compiled code, saving time and resources.
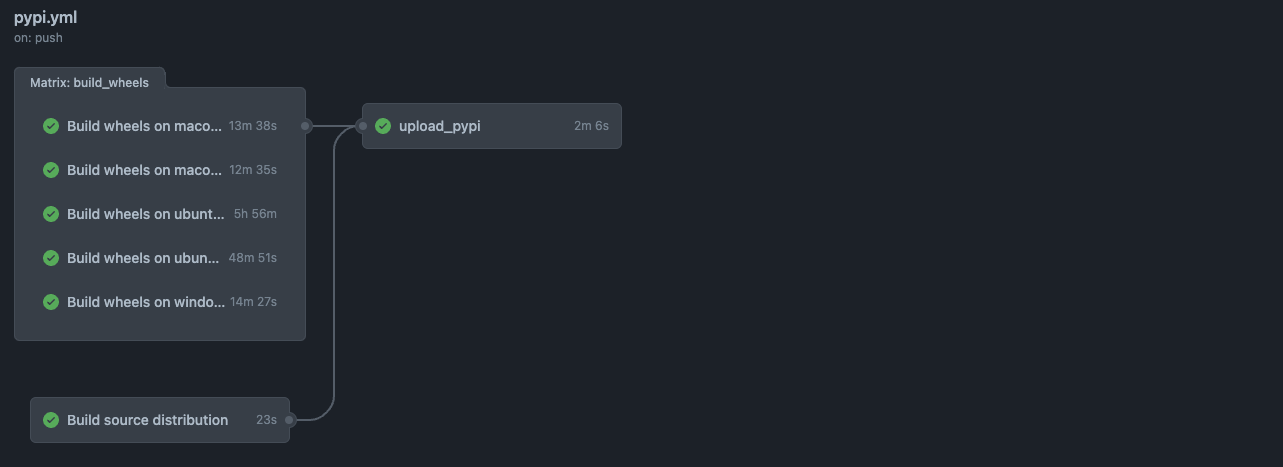
Here is an example of a .yml file that can be used with GitHub Actions to build Python wheels with Rust binding using cibuildwheel.
jobs:
build_wheels:
name: Build wheels on ${{ matrix.os }}
runs-on: ${{ matrix.os }}
strategy:
matrix:
os: [ubuntu-latest, windows-latest, macos-latest]
arch: [main, alt]
include:
# include the main arch for each os and the alt arch for each os
# ...
steps:
- uses: actions/checkout@v2
- name: set up rust
# use the rust toolchain
# add the target for the alt arch
# ...
- name: Build wheels
uses: pypa/cibuildwheel@v2.3.0
env:
CIBW_BUILD: "cp38-* cp39-* cp310-* cp311-*"
CIBW_BEFORE_BUILD: >
pip install setuptools-rust cython &&
rustup default nightly &&
rustup show
CIBW_SKIP: "*-musllinux_i686"
CIBW_ARCHS: ${{ matrix.alt_arch_name || 'auto' }}
CIBW_MANYLINUX_X86_64_IMAGE: "manylinux2014"
CIBW_MUSLLINUX_X86_64_IMAGE: "musllinux_1_1"
CIBW_MANYLINUX_AARCH64_IMAGE: "manylinux2014"
CIBW_MUSLLINUX_AARCH64_IMAGE: "musllinux_1_1"
CIBW_ENVIRONMENT: 'PATH="$HOME/.cargo/bin:$PATH"'
CIBW_ENVIRONMENT_LINUX: 'PATH="$HOME/.cargo/bin:$PATH" CARGO_NET_GIT_FETCH_WITH_CLI="true"'
CIBW_MANYLINUX_I686_IMAGE: "manylinux2014"
CIBW_ENVIRONMENT_WINDOWS: 'PATH="$UserProfile\.cargo\bin;$PATH"'
CIBW_BEFORE_BUILD_LINUX: >
pip install cython numpy setuptools wheel setuptools-rust &&
curl https://sh.rustup.rs -sSf | sh -s -- --default-toolchain=nightly --profile=minimal -y &&
rustup show
The full code is here.
Two notable environment variables in the configuration file are CIBW_SKIP and CIBW_ENVIRONMENT_LINUX.
The CIBW_SKIP environment variable specifies that the *-musllinux_i686 combination of operating system and architecture should be skipped during the build process. This is because rust is not available for the musllinux operating system on the i686 architecture.
The CIBW_ENVIRONMENT_LINUX environment variable sets the PATH and CARGO_NET_GIT_FETCH_WITH_CLI environment variables for Linux environments. The PATH variable is set to include the $HOME/.cargo/bin directory, as in the CIBW_ENVIRONMENT variable. The CARGO_NET_GIT_FETCH_WITH_CLI variable is set to true to fix the error:
cargo rustc --lib --message-format=json-render-diagnostics --manifest-path Cargo.toml --release -v --features pyo3/extension-module -- --crate-type cdylibfailed with code -9
which can occur when building Rust extensions on Linux. This solution was found in the following GitHub issue.
ET VOILÀ ! It work’s !
Wrap-up
This blog post discussed how we extended the River stats module with Rust using PyO3. We motivated the need for better performance in the River stats module. We explained how we addressed this issue by creating the watermill crate, which contains the stats module of River implemented in Rust.
We are excited to use Rust in the River codebase for several reasons. Rust provides excellent performances, as demonstrated by the significant improvements we saw in the stats module. This has allowed us to progress faster and achieve our goals more efficiently.
If you have any questions, please do not hesitate to contact me by email or on Twitter.
If you want discuss about river, you can join the Discord channel.